L’ analyse des données est un domaine fascinant et en constante évolution qui joue un rôle crucial dans de nombreux secteurs tels que la science, l’ entreprise, la santé, et bien d’autres. Elle est devenue une pierre angulaire dans la prise de décision informée et la résolution de problèmes complexes. En outre l’analyse des données est un processus qui vise à inspecter, nettoyer, transformer et modéliser des données dans le but de découvrir des informations utiles, de conclure des informations, de soutenir la prise de décision, et de proposer des recommandations. Ce thème se propose d’explorer les divers aspects de l’analyse des données, mettant l’accent sur la découverte des tendances, la génération d’insights et l’ application pratique dans divers domaines.
1- Etat de l’art de l’analyse des données
L’ état de l’art de l’analyse des données représente une exploration approfondie des tendances actuelles, des méthodes, des outils et des développements dans le domaine de l’ analyse des données. Voici quelques éléments clés à considérer lorsque l’ on aborde l’ état de l’ art de l’ analyse des données.
1.1 – Evolution Historique
L’ évolution historique de l’analyse des données remonte à plusieurs siècles, mais le domaine a connu une transformation significative avec l’avènement de l’informatique et des technologies modernes. Les débuts de l ‘ analyse des données peuvent être retracés aux travaux de statisticiens tels que Gauss, Laplace et Pearson. Les méthodes statistiques classiques, telles que la régression linéaire et la distribution normale, ont été développées. Avec l’avènement de l’informatique, les méthodes d’analyse des données ont commencé à s’appuyer sur des calculs automatisés. Les ordinateurs ont permis des calculs plus rapides, facilitant ainsi l’application de techniques statistiques avancées. Les années 70 sont marquer par L’émergence des bases de données relationnelles lequel a ouvert la voie à une gestion plus efficace des données. Cela a facilité la manipulation et l’analyse de grandes quantités d’informations. Ensuite on assiste à l’émergence du Business Intelligence qui est devenue un domaine clé de l’analyse des données, avec des outils spécifiques pour la collecte, l’analyse et la visualisation des données dans un contexte commercial. L’émergence du data Mining et des techniques de machine Learning a introduit de nouvelles approches pour découvrir des modèles dans les données, allant au-delà des méthodes statistiques classiques. Dans les années 2000 on assiste à L’explosion des volumes de données ce qui a conduit à la naissance de l’ère du Big Data. Les technologies comme Hadoop ont permis de stocker et d’analyser des ensembles de données massifs, ouvrant de nouvelles perspectives pour l’analyse des données. Ensuite l’avènement des outils de visualisation des données interactive est devenue essentielle pour la compréhension rapide des tendances. Des outils comme Tableau ont permis aux utilisateurs de créer des graphiques dynamiques et interactifs. Les années 2010 marque la naissance de l’intelligence artificielle, y compris le Deep Learning. Elle a révolutionné l’analyse des données en permettant des prédictions plus avancées et une automatisation accrue des processus analytiques. De nos jours la pratique de L’analyse en temps réel devient de plus en plus importante, permettant aux organisations de prendre des décisions basées sur des données en temps réel.
1.2 – Les outils et les technologies émergents dans le domaine
Le domaine de l’analyse des données est en constante évolution, avec l’émergence continue de nouveaux outils et technologies pour répondre aux demandes croissantes en matière de traitement et d’analyse des données. Voici quelques-uns des outils et technologies émergents dans le domaine de l’analyse des données : Apache Spark, Snowflake, Knime, Rapidminer, Python, R …
2 – Méthodologies d’Analyse des Données
Les méthodologies d’analyse des données décrivent les différentes approches et étapes utilisées pour explorer, nettoyer, modéliser et interpréter les données en vue de tirer des conclusions exploitables. Voici quelques-unes des principales méthodologies d’analyse des données.
2.1 – Définition des objectifs
Avant de commencer toute analyse, il est crucial de définir clairement les objectifs de l’analyse des données. Quelles questions souhaitez-vous répondre ? Quel est le problème que vous essayez de résoudre ?
2.2 – Collecte des données
Rassembler les données nécessaires en utilisant des méthodes appropriées. Cela peut inclure la collecte de données primaires (directement à partir de sources originales) ou la collecte de données secondaires (à partir de sources existantes).
2.3 – Nettoyage des données
Le nettoyage des données est une étape cruciale dans le processus d’analyse des données. Des données propres et bien préparées sont essentielles pour garantir des résultats précis et fiables. Celle-ci peut se résumer de la façon suivante :
- Comprendre les Données
- Examiner la structure des données
- Identifier les Types de variables (numériques, catégoriques, temporelles, etc.)
- Comprendre la signification de chaque variable
- Gestion des Valeurs Manquantes
- Identifier les Valeurs Manquantes dans les données
- Décider de la meilleure approche pour traiter les valeurs manquantes (suppression, imputation, etc.)
- Utiliser des techniques d’imputation telles que la moyenne, la médiane ou des méthodes plus avancées en fonction du contexte.
- Gestion des Valeurs Aberrantes (Outliers)
- Identifier les valeurs aberrantes qui pourraient fausser l’analyse.
- Décider de la façon de traiter les valeurs aberrantes (suppression, transformation, etc.)
- Normalisation des Données
- Mettre à l’échelle les variables numériques pour les rendre comparables.
- Utiliser des techniques telles que la standardisation ou la normalisation min-max
- Gestion des duplicats
- Identifier et supprimer les lignes en double.
- S’assurer que les données uniques sont traitées de manière appropriée.
- Conversion des types de Données
- S’assurer que les types de données sont appropriés pour chaque variable.
- Convertir les données si nécessaire (par exemple, convertir une variable de texte en numérique)
Le nettoyage des données garantit la qualité des données avant de procéder à l’analyse. En suivant ces étapes, vous pouvez améliorer la qualité de vos données et garantir une base solide pour vos analyses ultérieures.
2.4 – Exploration des Données (Exploratory Data Analysis – EDA)
L’exploration visuelle des données est une étape essentielle dans le processus d’analyse des données. Elle implique l’utilisation de graphiques, de tableaux de bord interactifs et d’autres représentations visuelles pour comprendre la structure, les tendances et les schémas des données. L’exploration visuelle des Données permet de remplir les objectifs suivants :
- Identification des tendances : on peut utiliser des graphiques tels que les courbes temporelles, les diagrammes en barres et les nuages de points pour détecter des tendances et des modèles dans les données.
- Détection d’Outliers : est utiliser pour Identifier visuellement les valeurs aberrantes ou les anomalies qui pourraient indiquer des erreurs de collecte de données ou des comportements inhabituels.
- Compréhension de la Distribution : à partir des histogrammes, des boîtes à moustaches (box plots) et des densités on peut comprendre la distribution des données et détecter la présence de clusters.
- Relation entre Variables : on peut créer des graphiques de dispersion et des matrices de corrélation pour explorer les relations entre différentes variables.
- Visualisation Multidimensionnelle : on peut utiliser des techniques de réduction de dimension comme l’analyse en composantes principales (PCA) pour visualiser des ensembles de données multidimensionnels.
- Evolution Temporelle : on peut utiliser des graphiques en ligne temporelle pour observer les changements au fil du temps et détecter des motifs saisonniers ou cycliques.
- Segmentation et Clustering : appliquer des techniques de clustering et utiliser des graphiques de segmentation pour identifier des groupes de données similaires.
2.5 – Préparation des Données (Data Pre-processing)
La préparation des données, également appelée data pre-processing, est une étape essentielle dans le processus d’analyse des données. Elle vise à transformer les données brutes en un format qui peut être utilisé de manière plus efficace pour des analyses ultérieures. Data Preprocessing comporte plusieurs étapes à savoir :
- Data Transformation
Les données ont souvent besoin d’être transformées pour répondre aux exigences de l’analyse ou de la modélisation. Cela peut inclure la conversion de données catégorielles sous forme numérique grâce à des techniques d’encodage. Par conséquent les caractéristiques numériques peuvent nécessiter une normalisation.
- Sélection des variables (Feature Selection)
Parfois, les jeux de données contiennent de nombreuses variables, dont certaines peuvent ne pas contribuer de manière significative à l’analyse ou même introduire du bruit. Les techniques de sélection des caractéristiques permettent d’identifier et de retenir les variables les plus pertinentes. Il permet d’améliorer l’efficacité du modèle.
- Fractionnement des données (Data Splitting)
Les données sont divisées en ensembles d’apprentissage (training set) et de test (test set) pour évaluer correctement les modèles d’apprentissage automatique. Le training set est utilisé pour l’entraînement du modèle, tandis que le test set est réservé à l’évaluation du modèle.
- Standardisation des données
La standardisation des données garantit que les différentes unités de mesure n’affectent pas les performances du modèle. Cette étape consiste à convertir les variables pour les rendre comparables et empêcher qu’une caractéristique ne domine les autres dans le modèle.
- Validation des données
Il est essentiel de valider et de vérifier en permanence la qualité des données à chaque étape du processus de prétraitement des données. Ainsi, cette étape permet de s’assurer que les données s’alignent sur les objectifs d’analyse ou de modélisation.
- Choix des Méthodes d’analyse
Sélectionner les méthodes d’analyse appropriées en fonction des objectifs et du type de données. Cela peut inclure des méthodes statistiques, des algorithmes d’apprentissage automatique (Machine Learning, Deep Learning…), des analyses temporelles, etc.
- Modélisation
Appliquer les modèles d’analyse choisis aux données pour générer des résultats. Cela peut impliquer la formation de modèles prédictifs, la création de clusters, ou d’autres techniques selon le contexte
- Interprétation des Résultats
Comprendre et interpréter les résultats de l’analyse en relation avec les objectifs initiaux. Cela peut impliquer l’identification de variables importantes, la compréhension des relations entre les facteurs, etc.
- Communication des Résultats
Présenter les conclusions de manière claire et compréhensible pour les parties prenantes. Cela peut inclure des rapports, des visualisations, des tableaux de bord interactifs, etc.
3. Applications de l’analyse de Données
L’analyse de données à une gamme étendue d’applications dans divers domaines. On peut citer entre autres : Business Intelligence (BI) : l’objectif de l’analyse de données dans le BI est de prendre des décisions basées sur des données pour améliorer les performances commerciales. Elle peut être appliquer dans diffèrent domaines tel que analyses de rentabilité, suivi des indicateurs de performance, prévisions de ventes, segmentation de la clientèle, … Finance : l’objectif de l’analyse de données dans la Finance est d’évaluer les performances financières, gérer les risques, détecter les fraudes. Comme application on peut citer l’analyse de portefeuille, modèles de risque, détection de fraudes, prévisions financières etc. Marketing : l’objectif est de cibler efficacement les clients, mesurer l’efficacité des campagnes. L’analyse de données peut être utiliser pour la segmentation de la clientèle, l’analyse du retour sur investissement, recommandations personnalisées, analyse de sentiment etc. E-commerce : améliorer l’expérience utilisateur, optimiser l’inventaire, personnaliser les recommandations. Comme domaine d’application de l’analyse de données on peut citer la Recommandations de produits, analyse du comportement des utilisateurs, prévisions de demandes.
Ces applications montrent la diversité des domaines où l’analyse de données peut avoir un impact significatif, contribuant à une prise de décision plus informée, à des processus plus efficaces et à une compréhension approfondie des phénomènes complexes. L’analyse des données continue de remodeler notre compréhension du monde qui nous entoure et de révolutionner la manière dont les organisations opèrent. Ce thème met en lumière l’importance croissante de l’analyse des données, offrant une perspective approfondie sur ses méthodologies, ses applications et ses implications.
4 – Cas pratique : : Cas d’ une institution Bancaire Portugaise
Objectif
Quel catégorie spécifique de clients est le plus susceptible de souscrire à un nouveau produit de la banque ? Afin de répondre à cette question nous allons utiliser les modèles d’analyse afin de prédire la catégorie de client qui pourra être intéresser par le produit et ensuite nous allons effectuer une comparaison entre les différents modèles afin de choisir le modèle ayant le taux de prédiction élevé. Cette étude est basée sur une enquête marketing réaliser par la banque donc les résultats sont enregistrés dans une base de données
Description des Données
l’ensemble de données que nous allons utiliser dans notre analyse provient d’une campagne de Marketing d’une institution bancaire portugaise. La base de données provient de la Plateforme UIC Irvine Machine Learning Repository (https://archive.ics.uci.edu/). Ces données ont été recueillies par téléphone de mai 2008 à novembre 2010. La base de données contient 45211 Observations et 17 Variables, c’est-à-dire 16 variables d’entrée et la variable cible y (réponse « Oui » ou « Nom ». Les variables d’entrée (Variables explicative) fournissent des informations sur chaque client, telles que l’âge, le mariage le statut, l’emploi et le niveau d’éducation. Les intrants sont subdivisés en données qualitatives et Variables quantitatives.
Pour les variables numériques on distingue : Age : l’âge de chaque client de la banque; Balance : Le solde annuel moyen en euros; Pdays : le nombre de jours écoulés depuis que le client a été contactée au sujet de la campagne précédente; Duration : la durée de contact de chaque client en secondes; Campaign : le nombre de contacts effectués au cours de cette campagne et pour chaque cliente; Previous : le nombre de contacts effectués avant la campagne; Day : le jour de la semaine depuis le dernier contact
Concernant les variables Qualitatives : Job : comme emploi, il y a l’administration, les chômeurs, la direction, la femme de ménage, entrepreneur, étudiant, ouvrier, indépendant, retraité, technicien, et l’emploi inconnu enregistrés; Marital : l’état matrimonial (marié, célibataire et divorcé); Education : Il est classé en 4 classes à savoir tertiaire, secondaire, primaire, et classe inconnue; Loan : si le client a un prêt personnel ou non; Default : il s’agit de savoir si le client est en défaut de paiement ou non; Housing : le client a un prêt au logement ou pas de prêt; Contact : il s’agit de la façon dont les clientes ont été contactées (inconnu, cellulaire,
téléphone); Poutcome : C’est le résultat de la campagne de marketing précédente et c’est Classés en 4 catégories à savoir : Inconnu, Échec, Autre, Succès; Month : Il s’agit du mois de l’année où le dernier contact a été établi.
4.1 – Exploration des données (EDA)
- Variables Numériques
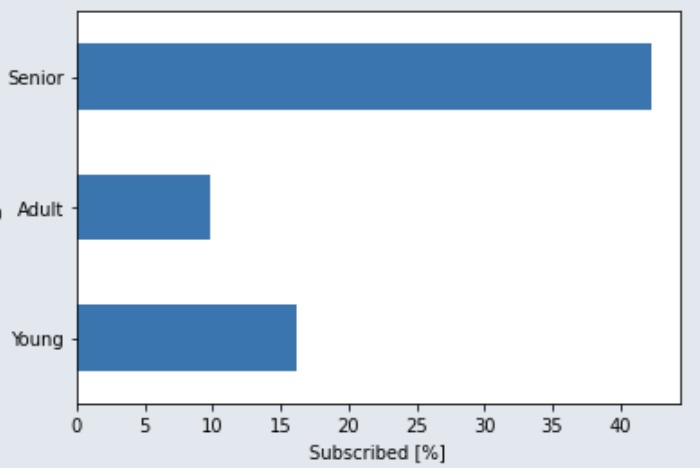
Nous allons représenter graphiquement certaines variables numériques, en nous limitant à quelques-unes. Pour l’âge, nous avons créé trois catégories : « Senior » pour les clients de plus de 60 ans, « Adulte » pour ceux entre 30 et 60 ans, et « Jeunes » pour les moins de 30 ans, comme le montre le graphique ci-dessous.
Selon les graphique ci-dessous, le groupe d’âge le plus susceptible de souscrire au nouveau produit est le groupe des seniors, qui représente environ 43 % des clients.
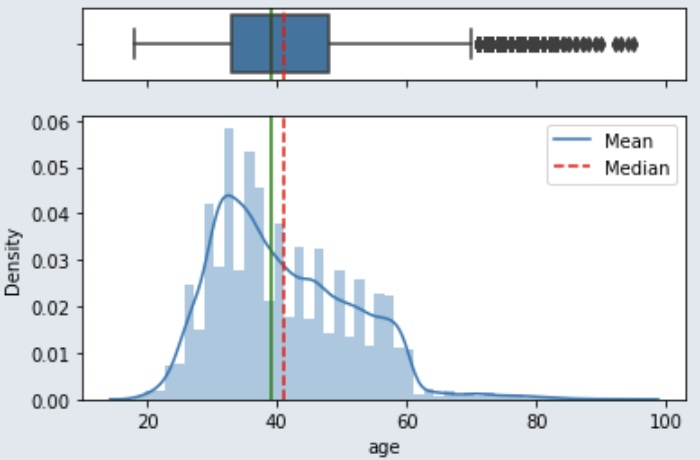
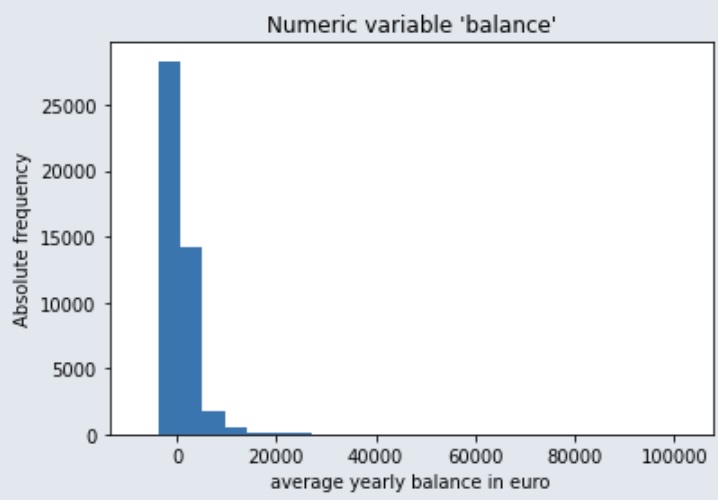
Balance
Le salaire des personnes interrogées varie entre 0 et environ 210 000, ce qui signifie que la majorité ne dispose pas d’un salaire très élevé.
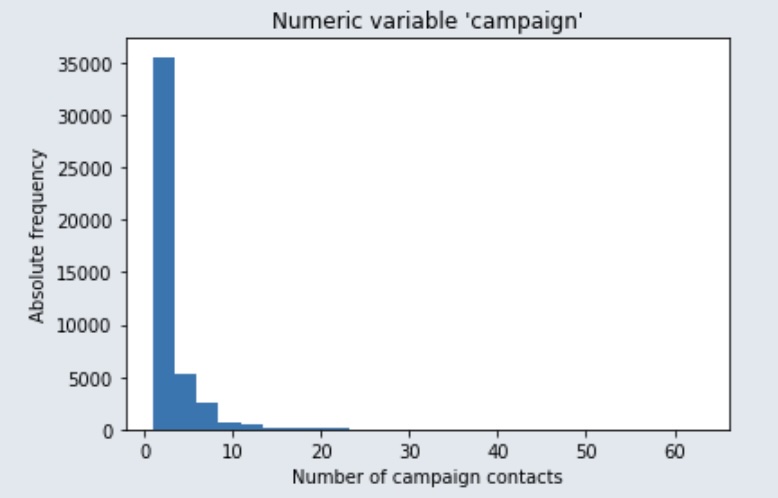
Campaign
Le graphique ci-dessous montre le nombre de contacts effectués lors de la campagne, et nous pouvons observer que le plus grand nombre de personnes contactées est de 35 000.
- Variables catégorielles
La variable catégorielle « Job » compte 12 valeurs uniques, comme le montre la figure ci-contre, et « blue-collar » est l’emploi le plus courant. En plus de cela, il y a une catégorie étiquetée « inconnue » qui doit être considérée comme un ensemble de valeurs manquantes. La variable « matrimonial » comprend trois catégories (marié, célibataire, divorcé), et la catégorie la plus susceptible de souscrire est celle des personnes mariées.
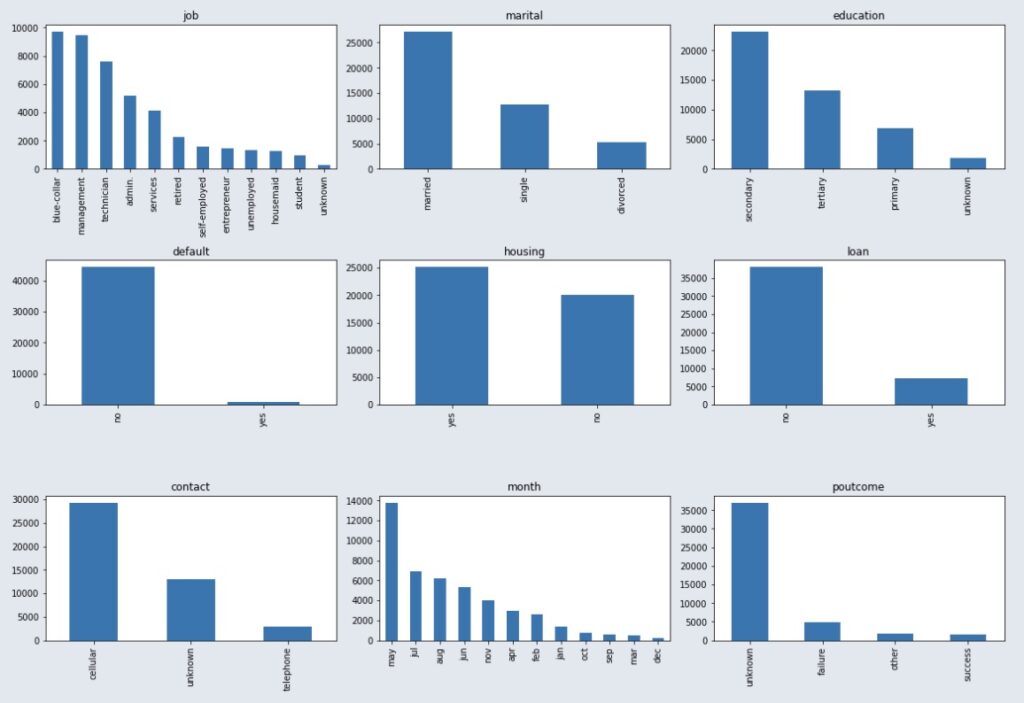
4.2 – Nettoyage des données
Avant de pouvoir entraîner les modèles sur cette base de données, il est important de nettoyer les données, car elles peuvent contenir des valeurs aberrantes ou manquantes qui peuvent conduire à une mauvaise estimation des modèles. Pour les variables numériques, selon la représentation graphique, on constate qu’il n’y a pas de valeurs inconnues ou manquantes. En revanche, pour les variables catégorielles, nous avons noté qu’il existe des classes « inconnues » considérées comme des valeurs manquantes. Afin de ne pas supprimer ces observations, qui sont très importantes pour l’analyse, nous allons imputer ces classes « inconnues » à la catégorie ayant la plus grande fréquence. Cependant, pour la variable « poutcome », nous n’allons pas traiter la catégorie inconnue, car c’est la classe avec la fréquence la plus élevée.
4.3 – Préparation des données
Cette étape est cruciale pour la modélisation des données. Notre base de données possède plusieurs variables catégorielles, ce qui pose la question de savoir comment traiter ce genre de données : cela consiste à transformer ces données. Nous allons donc transformer chaque variable catégorielle en numérique en utilisant la méthode « the dummie » (encodage binaire et encodage à chaud). Par conséquent, toutes les variables numériques seront normalisées. Après l’étape de nettoyage des données et la transformation des variables, nous obtenons enfin une base de données avec 45 variables. L’étape suivante consiste à déterminer les variables qui peuvent être sélectionnées et lesquelles peuvent être supprimées pour la modélisation des données.
4.4 – Sélection des variables
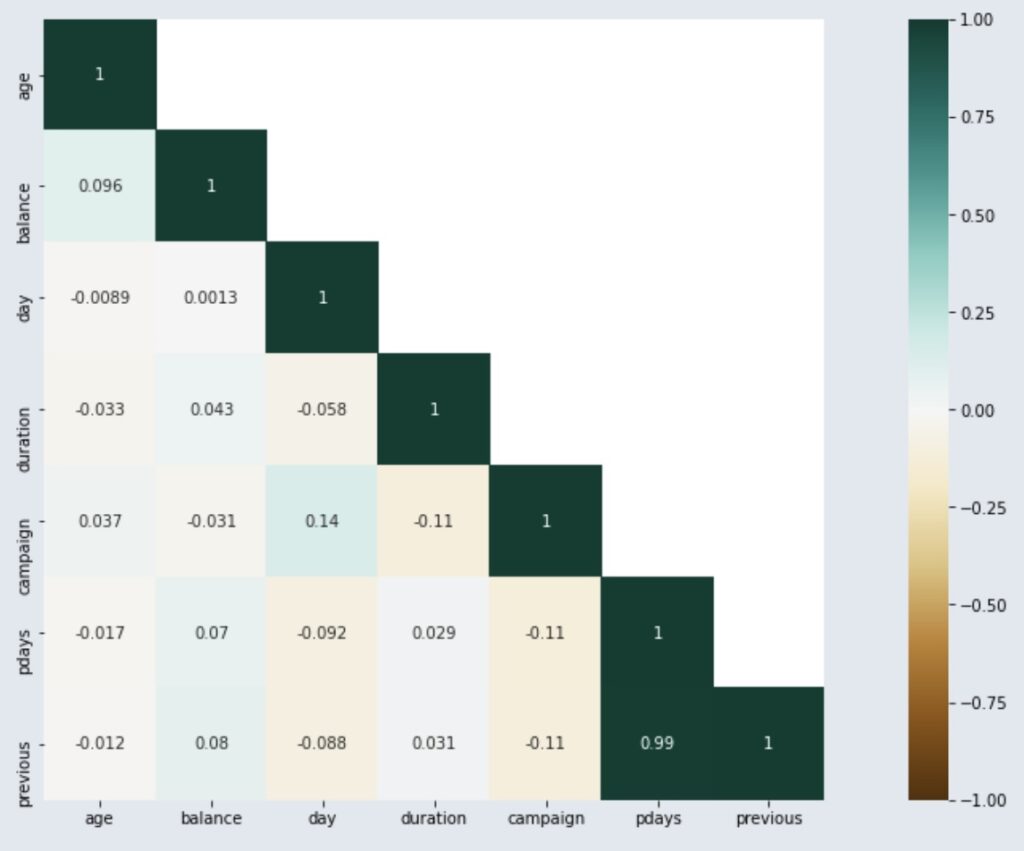
Afin de sélectionner les variables, nous allons calculer la corrélation de Pearson et la valeur de P. En ce qui concerne la corrélation de Pearson, le graphique ci-dessus montre que toutes les variables numériques sont linéairement indépendantes. Pour la valeur de P, si P ≤ 0,05, la corrélation est très faible, donc significative, et la variable peut être conservée; sinon, la variable doit être supprimée. Étant donné que la base de données dispose actuellement de 45 variables et qu’il est difficile de présenter toutes les valeurs de P dans cette analyse, nous allons uniquement présenter les variables pour lesquelles P ≥ 0,05 (variables qui seront supprimées de notre analyse car elles sont fortement significatives).
| Variable | P |
|---|---|
| self-employed | 0.86 |
| Education | 0.71 |
| divorced | 0.56 |
| admin | 0.23 |
| aug | 0.07 |
| jan | 0.06 |
| Technician | 0.06 |
4.5 – Modélisation
Dans cette section, nous aborderons la construction et l’évaluation de deux modèles prédictifs sur R : la régression logistique et le Support Vector Machine (SVM). L’objectif est de déterminer quel modèle prédit le mieux la probabilité de souscription des clients au nouveau produit bancaire.
La base de données nettoyée et transformée est d’abord divisée en deux sous-ensembles : 80 % pour l’ensemble d’apprentissage (training set) et 20 % pour l’ensemble de test (test set). Les ensembles d’apprentissage et de test sont ensuite normalisés et mis à l’échelle pour éliminer les valeurs aberrantes et améliorer la précision des modèles, en utilisant la commande « MinMaxScaler() ».
Le modèle de régression logistique est entraîné sur l’ensemble d’apprentissage avec une validation croisée (CV) ayant un paramètre de 0,1. Après l’entraînement, il obtient une précision de 0,843 et une AUC de 0,90. Le modèle SVM est également entraîné sur l’ensemble d’apprentissage avec une validation croisée (CV) de 10, et obtient une précision de 85 % et une AUC de 89,5 %.
Les performances des modèles sont mesurées en termes de précision et d’AUC. La précision indique la proportion de prédictions correctes parmi toutes les prédictions, tandis que l’AUC mesure la capacité du modèle à différencier entre les classes positives et négatives. Le modèle avec la meilleure performance, en termes de précision et d’AUC, sera sélectionné comme le modèle de prédiction optimal pour déterminer les clients susceptibles de souscrire au nouveau produit de la banque.

À partir des résultats obtenus, nous pouvons conclure que le SVM est le modèle de prédiction le plus approprié en raison de sa précision plus élevée. N.B. : Pour obtenir le détail du processus de détermination de la précision et de l’AUC, veuillez contacter l’équipe Campus Consulting, qui pourra vous fournir ces informations.
Dans ce projet, nous avons démontré l’application de l’analyse de données dans le domaine bancaire en utilisant différents algorithmes d’apprentissage à partir de la base de données de la banque portugaise. Grâce au meilleur modèle de prédiction, la banque pourra identifier et cibler les catégories de clients les plus susceptibles de souscrire au nouveau produit, et adapter sa politique de marketing direct en fonction de chaque catégorie cible. Nous anticipons ainsi une réduction des coûts associés aux campagnes de marketing direct.